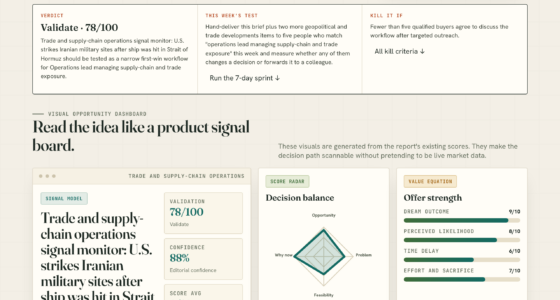
📊 Full opportunity report: The Real Cost Of A Local-Inference Rig In 2026 on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
In 2026, owning a local inference rig depends heavily on VRAM capacity and model size, with used GPUs like the RTX 3090 offering better value than newer, more expensive cards. Cost-effective multi-GPU setups and Apple Silicon options are emerging alternatives.
In 2026, the **cost of building a local inference rig** for large language models varies significantly based on VRAM capacity and model size, with key hardware choices influencing affordability and performance. This development matters because it impacts AI practitioners’ decision-making on whether to own or rent cloud-based models, affecting cost, privacy, and control.
The core factor determining local inference costs is **VRAM capacity**. Models fitting entirely within VRAM run at high speeds, while spilling into system RAM causes drastic performance drops, often by a factor of 5 to 20. For example, a 70B model requires roughly 43GB of memory at Q4 quantization, necessitating high-end GPUs or multi-GPU setups.
In 2026, **GPU choices** are driven by VRAM-per-dollar rather than raw compute power. Used RTX 3090 cards, with 24GB VRAM and prices around $600–850, offer superior value compared to the latest flagship cards like the RTX 5090, which costs about $2,000 and has 32GB VRAM. Multi-3090 configurations can pool VRAM to run larger models at a lower cost.
Hardware tiers align with model sizes: entry-level (~$750) for models up to 14B, mid-range (~$1,000–$1,500) for 26–32B models, and high-end (~$2,000+) for 70B models. For models exceeding 100B, multi-GPU rigs or large-memory Macs are necessary, making local inference less practical without significant investment.
The real cost of a local-inference rig
Owning beats renting for steady AI work — so what does a local rig cost in 2026? The unintuitive, good news: the most expensive build is almost never the smartest one. It all comes down to one rule.
The difference is only whether the weights fit. LLM inference is memory-bandwidth-bound — VRAM capacity is the hard limit you build around. Compute specs are mostly noise.
The squeeze reframes the rig like everything else in this series: discipline beats maximalism. VRAM is exactly the memory under most pressure, so over-buying it is the 128GB-“to-be-safe” trap, only worse per gigabyte. Take the cheap, high-value step to 24GB (the gateway to the 30B class), reach for used 3090s and MoE models, and use quantization to climb a tier without buying silicon. Sized right, the rig pays for itself against the cloud’s ever-rising hidden bill. Next: Apple Silicon’s quiet memory advantage.
Impact of VRAM and Hardware Choices on Cost-Effective Local AI
Understanding the true costs of local inference hardware in 2026 helps AI practitioners make informed decisions, balancing performance and budget. The emphasis on VRAM capacity over raw GPU speed shifts purchasing strategies toward used or multi-GPU setups, making local AI more accessible and affordable than previously thought. This influences privacy policies, cost management, and the future of on-premise AI deployment.
used NVIDIA RTX 3090 GPU for AI inference
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Hardware Trends and Model Sizes in 2026
In recent years, the AI hardware landscape has shifted from a focus on raw compute to VRAM capacity, driven by model size requirements. The 2026 memory crunch series highlights that models like 70B and larger demand significant VRAM, often exceeding single-GPU capacities, prompting a move toward multi-GPU rigs and used hardware. Additionally, Apple Silicon Macs with large unified memory pools are emerging as alternative platforms for large models, bypassing traditional GPU limitations.
Previous developments include the rise of quantized models (Q4, Q3) to reduce memory needs, and the realization that inference is bandwidth-bound, making VRAM capacity more critical than compute power. These trends shape the hardware choices and costs discussed here.
“For inference, VRAM capacity, not raw GPU speed, determines whether a model runs efficiently. The 2026 hardware landscape prioritizes VRAM-per-dollar over the latest flagship cards.”
— Thorsten Meyer
multi-GPU setup for AI models
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Cost and Performance Trade-offs for 2026
While the analysis suggests used GPUs like the RTX 3090 provide better value, the actual availability, warranty status, and long-term reliability of these cards remain uncertain. Additionally, the impact of new hardware releases or software optimizations on cost-efficiency is still developing, making precise cost projections challenging.
high VRAM graphics card for large language models
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Future Hardware Developments and Cost Optimization Strategies
In the coming months, hardware manufacturers may release new GPUs or memory solutions that shift the cost-performance balance further. Practitioners should monitor used hardware markets, software optimizations, and emerging platforms like Apple Silicon to adapt their inference setups accordingly. Further research will clarify the long-term affordability of multi-GPU rigs versus single high-end cards.
Apple Silicon Mac for AI inference
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
What is the main factor influencing local inference costs in 2026?
The primary factor is **VRAM capacity**, which determines whether a model can run efficiently on a given GPU. Models that fit entirely in VRAM perform much faster than those spilling into system RAM.
Are used GPUs like the RTX 3090 a good investment for local inference?
Yes, used RTX 3090 cards offer superior **VRAM-per-dollar** value and can be pooled in multi-GPU configurations, making them a cost-effective option for running large models in 2026.
What hardware tier is needed for 70B models?
Running 70B models typically requires a **32GB GPU** like the RTX 5090 or a multi-GPU setup with pooled VRAM, such as four used 3090s, to handle the memory demands efficiently.
How does Apple Silicon compare for local inference?
Apple Silicon Macs with large unified memory pools (e.g., 64GB) can run models that would otherwise need high-end GPUs, offering a different, potentially more affordable platform for large model inference.
Will hardware costs decrease or increase in the future?
While some used hardware remains affordable, the overall trend depends on new releases, supply chain factors, and software optimizations. Monitoring these developments will be key for cost planning.
Source: ThorstenMeyerAI.com